- Published on
Implementing Spatially-Grounded Document Retrieval via Patch-to-Region Propagation
- Authors

- Name
- Athos Georgiou
Late to the Party

Up until October 24th, 2024, I knew next to nothing about ColPali. That changed when I stumbled upon Qdrant's workshop on optimizing ColPali with Qdrant.
What struck me wasn't just the model itself; it was the elegance of late interaction. I myself was a bit late to the party, but you know what they say; the best time to learn about late interaction was a year ago. The second best time is now.
My wake-up call
The Problem with Page-Level Retrieval
A few months ago, I shared Snappy, a vision-first document retrieval system built on ColPali. Using the ColPali family of models, Snappy enables semantic search over PDFs, scanned documents, images, and more. It works great for exploratory search: you can find relevant documents quickly, even if they contain complex layouts, tables, or images.
But there was a problem. When asking specific questions like "What was the Q3 revenue?", Snappy would correctly identify the right page (maybe a financial report with multiple tables, headers, footnotes, and legal disclaimers) and return the entire page to a VLM or LLM for answer generation. Although this in principle worked, using a large topK value to ensure the right page was found, I was essentially handing over a firehose of irrelevant content to the VLM.
This has two main problems:
- Diluted Attention: LLMs have a limited attention budget. When you feed them an entire page, they have to sift through all the noise (headers, footers, unrelated tables) to find the actual answer. This makes it harder for them to focus on the relevant parts, leading to lower-quality answers.
- Increased Costs: LLMs charge based on the number of tokens processed. Feeding them entire pages means you're paying for a lot of irrelevant content. This drives up costs significantly, especially when scaling to many queries.
I realized the problem wasn't with vision-language models themselves. It's more about how we are using them. We are throwing away valuable spatial information that could help us pinpoint exactly where the answer was located on the page. I had to go back to the drawing board. And so, to the drawing board I went.
And then I took a little nap. On the drawing board...
Discovering ColModernVBERT
About 2 months ago I saw ColModernVBERT on HuggingFace, which is the late-interaction version of ModernVBERT, fine-tuned for visual document retrieval tasks. Quite a phenomenal achievement as it is a suite of 250M-parameter vision-language encoders, achieving state-of-the-art performance in this size class, matching the performance of models up to 10x larger.
I immediately set up a FastAPI service to serve ColModernVBERT embeddings, and started testing it out on various document collections in Snappy. I was quite impressed with its retrieval quality and speed, so I decided to replace my existing ColQwen2.5 model with it. But there was one fundamental piece of functionality the ColModernVBERT model was missing. Due to its dependence of the ColIdefics3Processor, which at the time didn't include an implementation for get_n_patches and get_image_mask, I couldn't access patch-level similarity scores like I could with other ColPali models. That caused a particular problem in Snappy; It broke my implementation using Mean Pooling & Reranking with Qdrant, because it required access to patch-level scores to rerank candidate pages. But at that time I didn't think much of it and just proceeded with using ColModernVBERT for page-level retrieval and disabled the Mean pooling & reranking functionality. And for a time, that was that.
The OCR Breakthrough
Last month, a number of extremely capable OCR models emerged on HuggingFace, such as PaddleOCR and DeepSeek-OCR. What's really cool about these models is that along with precisely extracting text, tables and figures, they also provide precise bounding boxes for every detected element. This means they know where each piece of content is located on the page. And that got me thinking: what if I could combine ColPali's patch-level attention with OCR's bounding boxes to enable region-level retrieval? But, how?
EUREKA!
I rushed to the ColPali Repo and raised a new PR: Implement-interpretability-maps-for-colmodernvbert, in hopes of adding the missing functionality to extract patch-level similarity scores from ColModernVBERT. With that in place, I would finally be able to experiment with region-level retrieval in Snappy again. Off-course, I could have just used ColQwen2.5 which already had that functionality, but I really wanted to see ColModernVBERT working in Snappy, given its superior performance.
From PR to Preprint
Let me tell you what, it wasn't easy for a boomer like me to figure this out, but after lots of searching and scribbling, the PR was accepted and merged after a few days by none other than the man himself, Manuel Faysse, one of the first core contributors to the ColPali project. And through that learning process, I felt I had something going on, larger than just a toy project. So, I threw myself into research headfirst.
Yesterday, my paper, Spatially-Grounded Document Retrieval via Patch-to-Region Relevance Propagation, was released on arXiv. In it, I present a novel method for combining ColPali's patch-level attention with OCR bounding boxes to enable precise region-level document retrieval during inference time, and without any additional training.
Here's how it works:
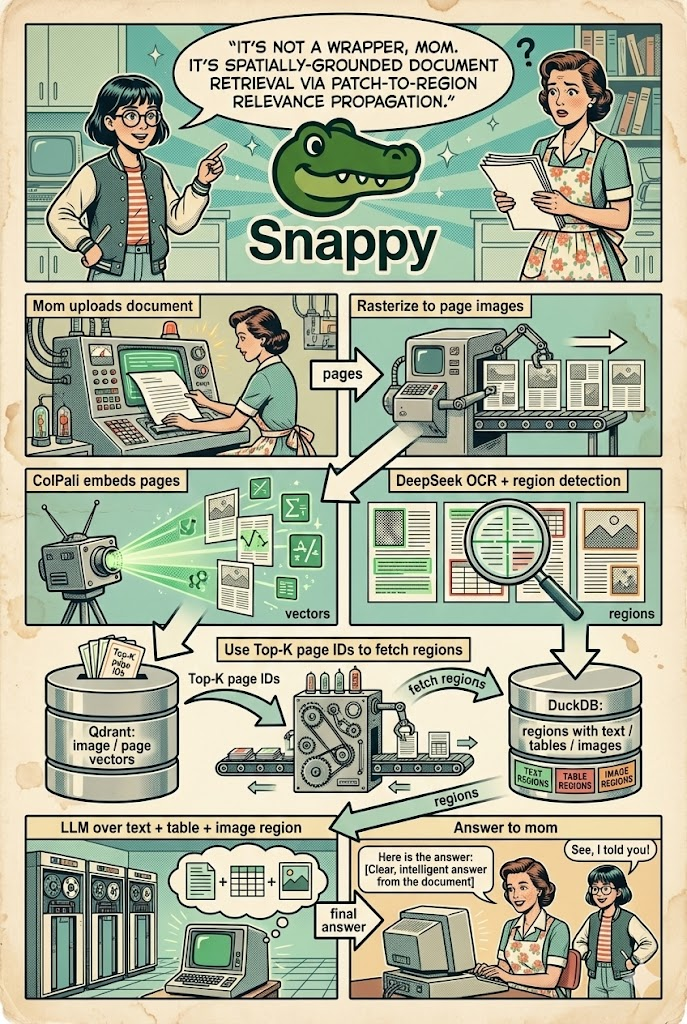
But before diving into the implementation details, it's important to understand what ColPali already knows about document structure and how we can leverage that knowledge.
Understanding What ColPali Already Knows
While building Snappy, I spent a lot of time staring at ColPali's internal workings. The model embeds each page as a 32×32 grid of patches (1,024 patch embeddings per page, plus 6 instruction token embeddings for a total of 1,030), each patch representing a 14×14 pixel region. When you query the system, ColPali computes similarity between each query token and every patch using a late interaction mechanism called MaxSim.

The magic is in those patch scores. They form a spatial heatmap showing exactly where on the page the model is paying attention. For each query, the patches overlapping that specific region light up with high similarity scores while ignoring headers, page numbers, and other legal boilerplate. The model knows where the answer is.
But then we throw that information away. We sum all the patch scores into a single page-level score, use it for ranking, and return the entire page. The spatial information (the most valuable signal for precise retrieval) gets discarded.
Meanwhile, OCR systems like PaddleOCR or DeepSeek-OCR extract text with precise bounding boxes. They tell you that a specific table occupies pixels (100, 500) to (800, 900), and that each cell within it has its own coordinates. This structural information is incredibly valuable; it preserves the semantic organization of the document.
The problem? OCR has no idea which regions matter for a given query. It's spatially precise but semantically blind.
When I tested Snappy on a collection of medical records, asking "What dosage was prescribed for hypertension?", the system would return an entire patient chart page containing:
- Patient demographics and insurance information
- Medication history for multiple conditions
- Vital signs from various visits
- Allergy warnings and contraindications
- Provider notes and signatures
- Administrative timestamps

The actual answer (a single line in the medications table) represented about 0.5% of the content. The LLM had to process 200× more tokens than necessary, costing 200× more, taking 200× longer, and competing for attention with 199 parts noise to 1 part signal.
I realized I didn't need to train a new model or annotate data. The information I needed was already there: ColPali's spatial attention + OCR's structural bounding boxes. I just needed to connect them.
Building the Bridge: Patch Scores Meet Bounding Boxes
The solution turned out to be conceptually simple: map ColPali's patch scores to OCR bounding boxes through coordinate alignment.
ColPali tells me which 14×14 pixel patches are relevant. OCR tells me which pixels contain which content regions. If I can figure out which patches overlap with which regions, I can rank regions by their aggregated patch scores, combining the semantic understanding of vision models with the structural precision of OCR.
The implementation required solving the coordinate mapping problem. ColPali operates on a 448×448 normalized input resolution with a 32×32 patch grid. OCR systems work with native document coordinates (often 1654×2339 pixels for a typical scanned page). I needed to:
- Transform OCR bounding boxes to ColPali's coordinate space
- Compute intersection-over-union (IoU) between each region and each patch
- Weight each patch's contribution to a region by its IoU
- Rank regions by their weighted patch scores

This approach operates in two stages:
Candidate Retrieval: Compress patch embeddings via mean pooling to obtain page-level embeddings. This enables efficient approximate nearest neighbor search to retrieve the top-K candidate pages.
Region Reranking: For each candidate page, compute full patch-level similarity and propagate scores to OCR regions. Regions are ranked by their relevance scores, and only the top-k regions are returned.
Coordinate Mapping
The key lies in formalizing the coordinate mapping between vision transformer patch grids and OCR bounding boxes. ColPali encodes each page as a grid of 32×32 patch embeddings over a 448×448 input resolution. Each patch corresponds to a 14×14 pixel region.
Given a query, the system computes similarity between each query token and every patch, producing a spatial heatmap of relevance. Rather than simply summing these scores (as ColPali does for page-level ranking), I use them as spatial relevance filters. For each OCR region, I calculate the overlap between its bounding box and the high-scoring patches, weighting each patch's contribution by its intersection-over-union (IoU) with the region.
The region relevance score is computed as:
rel(q, r) = Σ IoU(region_bbox, patch_bbox) × patch_score
This elegantly propagates VLM attention to structurally coherent regions, combining the semantic understanding of vision-language models with the precise localization of OCR.
Infrastructure
The two-stage retrieval pipeline leverages Qdrant's native multivector support to store both mean-pooled page embeddings and full patch-level embeddings. Qdrant's late-interaction reranking capability enables efficient MaxSim computation during the second stage, while binary quantization reduces storage overhead by approximately 32× without significant retrieval degradation (critical when storing 1,030 embeddings per page).
Key Advantages
This hybrid approach delivers three main benefits:
1. Training-Free Operation: The system operates entirely at inference time without requiring additional training, unlike methods such as RegionRAG (which uses a hybrid supervision strategy combining manually annotated bounding boxes from labeled data with weakly-supervised pseudo-labels from unlabeled data for region-level contrastive learning). This flexibility means the same approach works with any OCR system providing bounding boxes and any ColPali-family model.
2. Substantial Efficiency Gains: For typical document parameters (15 regions per page, returning 3 top regions), the expected context reduction factor is at least 5× (15 regions / 3 returned = 5×), translating directly to proportional reductions in LLM inference cost, response latency, and attention dilution. Under moderate assumptions about patch score correlation with relevance (relevant content occupying ~20% of page area with 70% of attention mass), this predicts signal-to-noise ratio (SNR) improvements of up to 14× compared to page-level retrieval.
3. Superior Precision-Efficiency Trade-off: Unlike existing approaches, this method achieves both low context cost and high precision simultaneously, as shown in the comparison below.
| Method | Context Cost | Precision | Best Use Case |
|---|---|---|---|
| ColPali (page-level) | High (1.0×) | Low (6.7%) | Page identification |
| OCR + BM25 | Low (0.2×) | Low (6.7%) | Keyword matching |
| OCR + Dense | Low (0.2×) | Low-Med | Semantic text search |
| Hybrid (mine) | Low (0.2×) | High (25-60%) | Precise RAG |

Note: Precision values represent the fraction of returned content that is relevant to the query. The 6.7% baseline (1/15 regions) assumes uniform relevance across regions. The hybrid approach's 25-60% precision range reflects variance across query types: structured data queries (tables, figures) achieve 50-60% precision, while unstructured text queries achieve 25-40% precision, depending on content concentration within regions.
Practical Considerations
Note on Empirical Validation: The precision values and efficiency gains presented in this post are based on theoretical analysis and initial testing on document collections, evidenced in the paper. Comprehensive benchmarking on standard datasets is currently in progress to quantify performance across diverse document types and query patterns and will be included in future revisions of the paper.
Use Cases
This approach works particularly well for:
Financial document analysis: Extracting specific metrics from reports, earnings releases, and filings
- Example queries: "What was the operating margin in Q3 2024?", "Find the debt-to-equity ratio in the latest 10-K", "Extract all revenue figures by segment"
Legal document review: Locating specific clauses with citation-bounded context for verifiable provenance
- Example queries: "Find force majeure clauses in Section 5", "What are the termination conditions?", "Locate all indemnification provisions"
Technical documentation: Answering questions about specifications, procedures, or configurations
- Example queries: "What is the maximum operating temperature for model X?", "Find the API rate limits", "What are the memory requirements?"
Healthcare and research: Retrieving specific findings, dosages, or methodology details from clinical documents
- Example queries: "What dosage was used in the Phase II trial?", "Find adverse events in Table 3", "What were the primary endpoints?"

Limitations to Consider
This approach has some inherent limitations worth understanding:
Patch resolution bounds: Small regions (below approximately 35×35 pixels at model resolution) achieve less than 50% localization precision due to patch quantization. Applications requiring fine-grained extraction may benefit from higher-resolution models.
OCR dependency: Region quality depends on OCR accuracy and segmentation. Poorly segmented regions will degrade retrieval quality regardless of VLM accuracy.
Two-stage information loss: Mean pooling in the first stage discards spatial information. Relevant pages with content concentrated in small regions could potentially be filtered out before region scoring.
Storage overhead: The system requires storing both page-level and patch-level embeddings. Qdrant's binary quantization mitigates this, achieving ~32× compression while preserving retrieval quality for the candidate retrieval stage.
Bringing It Back to Snappy

This research directly informed the latest version of Snappy. The system now implements this hybrid approach as an optional retrieval mode, giving you the choice between page-level retrieval (fast, good for exploratory search) and region-level retrieval (precise, better for question answering).
Under the hood, Snappy pairs a FastAPI backend with a ColPali embedding service and DeepSeek-OCR for visual grounding. I chose DeepSeek-OCR for its superior table detection and bounding box accuracy, but the approach works with any OCR system that provides bounding boxes: Tesseract, PaddleOCR, Azure Document Intelligence, you name it. The same applies to ColPali models; you can swap in ColModernVBERT, ColQwen2.5, or any other model in the family that supports patch-level interpretability.
The indexing pipeline processes documents in parallel: each page is rasterized, embedded via ColPali, and processed through OCR with visual grounding enabled. Both pooled page embeddings and full patch embeddings are stored as multivectors in Qdrant. Qdrant's support for late-interaction scoring and binary quantization makes this two-stage approach practical—without these optimizations, storing 1,030 128-dimensional embeddings per page would be prohibitively expensive. At query time, candidate pages are retrieved via efficient ANN search, then reranked at the region level using the stored patch embeddings.
The result? Queries like "Find the termination clause" return just the relevant contract section instead of the entire agreement. "What's the maximum operating temperature?" returns the specific specification table row, not the whole datasheet. Context consumption drops by 5×, costs shrink proportionally, and answer quality improves because the LLM isn't drowning in irrelevant content.
Try it yourself: github.com/athrael-soju/Snappy
What's Next
This work started from a practical frustration with page-level retrieval in Snappy and turned into a research contribution on spatial grounding for document retrieval. But I see it as just one step on the journey to publishing the paper in a journal or conference.
Right now, I'm running empirical evaluations on standard benchmarks to quantify the precision/recall trade-offs and understand where this approach excels versus where page-level retrieval might still be preferable. I'm also exploring extensions like:
- Cross-page region linking: Can we propagate relevance across pages for multi-page tables or figures? (Short answer: You bet we can! More on that soon!)
- Multi-hop reasoning across regions: Can we maintain coherence when answers span multiple regions?
- Quantitative Search: Can we extract structured data (tables, figures) directly from ranked regions for downstream analysis? (Spoiler: Yes, Snappy already implements early versions of this!)
If you're building document-centric AI applications, especially in domains where precision matters more than recall, this approach offers a practical path to better answer quality, lower costs, and verifiable provenance. No model retraining, no annotation burden, just smarter coordination between systems that already exist.
Check out Snappy if you want to try it yourself. And if you're working on similar problems or have ideas for improvements, I'd love to hear from you.
Special thanks to the ColPali team for their groundbreaking work on vision-language document retrieval and for the insightful discussions throughout this research. Building on your work has been a genuine pleasure.
I'm also grateful to Qdrant and Sabrina Aquino, whose workshop on ColPali optimization first introduced me to late-interaction vision models and unknowingly sparked what has become one of my biggest research passions. Qdrant's multivector support, mean pooling with late-interaction reranking, and binary quantization are what make Snappy's two-stage retrieval pipeline practical at scale.
References
ColPali: Efficient Document Retrieval with Vision Language Models Faysse, M., Sibille, H., Wu, T., Omrani, B., Viaud, G., Hudelot, C., & Colombo, P. (2024). arXiv preprint arXiv:2407.01449 https://arxiv.org/abs/2407.01449
RegionRAG: Region-level Retrieval-Augmented Generation for Visually-Rich Documents arXiv preprint arXiv:2510.27261 https://arxiv.org/abs/2510.27261
Spatially-Grounded Document Retrieval via Patch-to-Region Relevance Propagation Georgiou, A. (2025). arXiv preprint arXiv:2512.02660 https://arxiv.org/abs/2512.02660
Illuin Technology - ColPali Project https://www.illuin.tech/ https://github.com/illuin-tech/colpali
PaddleOCR: Awesome Multilingual OCR Toolkits PaddlePaddle Team https://github.com/PaddlePaddle/PaddleOCR
DeepSeek-OCR: Contexts Optical Compression DeepSeek AI (2025). https://github.com/deepseek-ai/DeepSeek-OCR
Tesseract OCR https://github.com/tesseract-ocr/tesseract
Snappy: Vision-First Document Retrieval System Georgiou, A. https://github.com/athrael-soju/Snappy
Qdrant: Vector Database for AI Applications https://qdrant.tech/
Qdrant Binary Quantization https://qdrant.tech/articles/binary-quantization/
Qdrant Multivector Support & Late Interaction https://qdrant.tech/documentation/concepts/vectors/
Advanced Retrieval with ColPali & Qdrant https://qdrant.tech/blog/qdrant-colpali/
This post refers to research presented in "Spatially-Grounded Document Retrieval via Patch-to-Region Relevance Propagation" by myself, Agathoklis Georgiou. For the full technical details including formal proofs and theoretical bounds, see the arXiv paper.